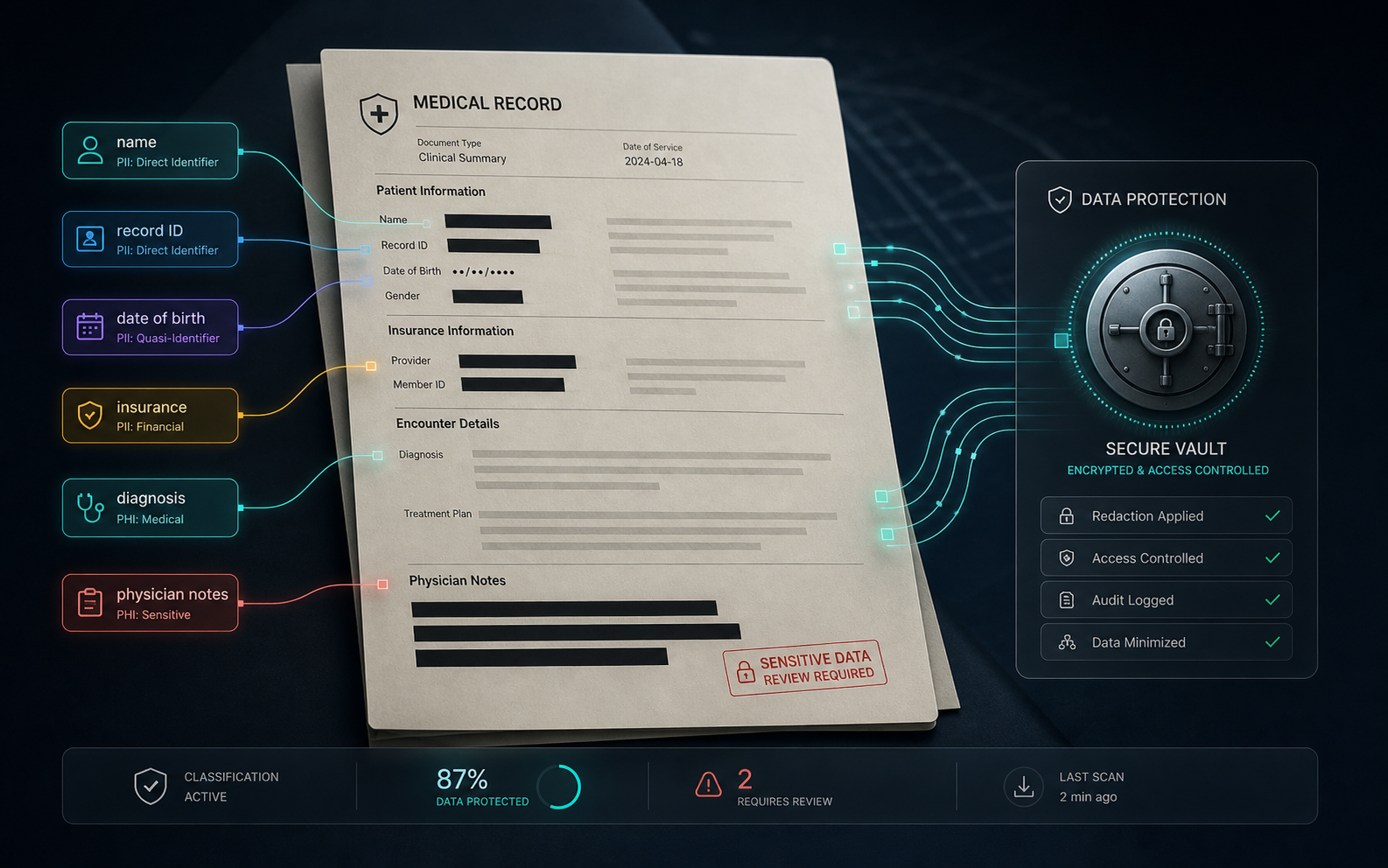
医療機関は、患者情報、保険情報、診療記録、事務データを含む膨大な文書を扱っています。クライアントは、システム全体のどこに機密性の高い個人情報が存在するかを把握し、プライバシー規制に基づいた適切な取り扱いを確保する必要がありました。
クライアントのリポジトリ全体の文書をスキャンし、氏名、住所、保険番号、カルテ識別子、その他の機密データカテゴリを識別するPII検出・分類システムを導入しました。文書を機密レベル別に分類し、システム間のデータフローをマッピングします。
NLPモデルは医療ドメイン向けにチューニングし、日本語の医療用語、多言語混在文書、カルテ特有のフォーマットパターンに対応しています。クライアントの既存データガバナンスポリシーに整合した段階的な分類スキームを実装しました。
このシステムはコンプライアンスチームに機密データの所在に関する継続的なインベントリを提供し、規制報告要件と内部データ保護監査の両方を支援しています。一度限りのスキャンではなく、継続的な監視ツールとして稼働しています。